
Introducing ImagenWorld: A Real World Benchmark for Image Generation and Editing
ImagenWorld is a large-scale benchmark created for exactly that purpose: to make model failures visible and explainable

We have all seen amazing generations, but what about the failures that never make it to the gallery? What if we could actually see where models make mistakes?
ImagenWorld is a large-scale benchmark created for exactly that purpose: to make model failures visible and explainable. It includes six major tasks that test different aspects of image generation and editing, ranging from text-to-image generation (TIG) to multiple-reference image editing (MRIE), where models must merge information from several reference images into one coherent result. By focusing on real-world tasks, ImagenWorld evaluates how models handle complex, multi-step, and open-ended instructions similar to what real users provide. All tasks span six diverse visual domains, providing a broad and realistic view of how models perform across different types of visual content.
How ImagenWorld Works
Instead of a single opaque score, ImagenWorld offers explainable evaluation.
Every image is rated by three annotators on four interpretable criteria:
Prompt Relevance: Does the output follow the instruction?
Aesthetic Quality: Is it visually coherent and appealing?
Content Coherence: Do all elements make logical sense together?
Artifacts: Are there distortions, glitches, or unreadable text?
Beyond scalar scores, annotators tag specific objects and segments responsible for errors: using Set-of-Mark (SoM) segmentation maps and vision-language-model-assisted object extraction. The result is a dataset where you can literally see why a model lost points.
Inside the Benchmark
ImagenWorld brings together six major tasks that span both image generation and editing, creating a complete picture of how models behave under real-world conditions.
TIG: Text-to-Image Generation
SRIG / MRIG: Single and Multi-Reference Image Generation
TIE: Text-Guided Image Editing
SRIE / MRIE: Single and Multi-Reference Image Editing
Each task is paired with six visual domains: artworks, photorealistic images, computer graphics, screenshots, information graphics, and textual graphics. This combination captures a wide range of complexity and style.
Every sample in ImagenWorld includes:
The original condition image(s) and prompt
Model outputs from different systems, both open-source and closed-source
Human annotations describing what went wrong (for example, object missing, text distorted, wrong color, and other issues)
Optional segmentation masks that highlight where those errors appear in the generated output
With more than 20,000 annotated examples, ImagenWorld reveals consistent patterns in model behavior and visual performance. It helps identify not only how good images look but also where and why they fail.
Explore tasks and visualizations: https://huggingface.co/spaces/TIGER-Lab/ImagenWorld-Visualizer
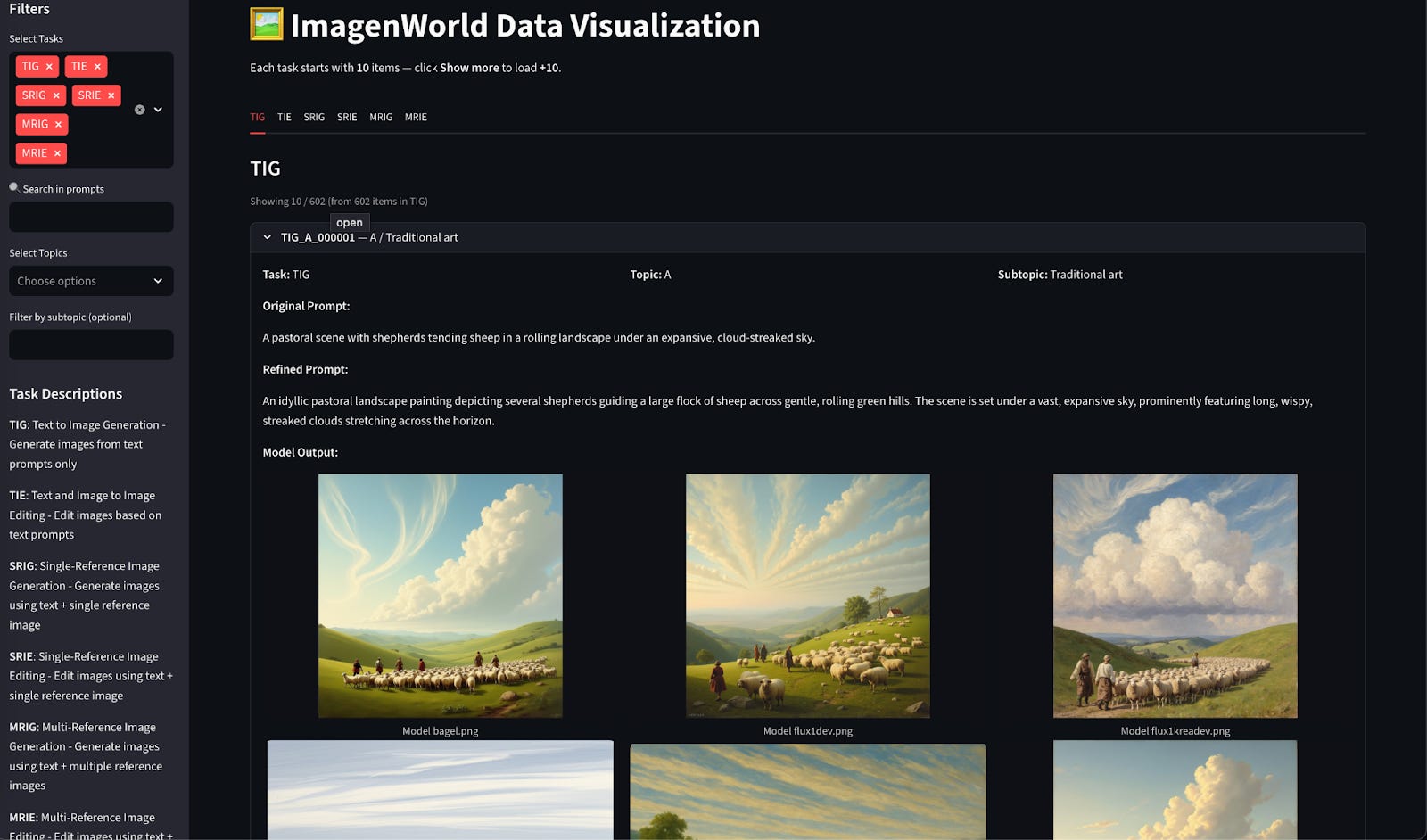
Find the dataset here:
https://huggingface.co/datasets/TIGER-Lab/ImagenWorld
Evaluating 14 Models Under One Protocol
We evaluated 14 state-of-the-art models spanning diffusion, autoregressive, and hybrid architectures: including both open-source and closed-source systems.
Each model was tested under the same unified pipeline across all six ImagenWorld tasks to ensure fair, reproducible comparison.
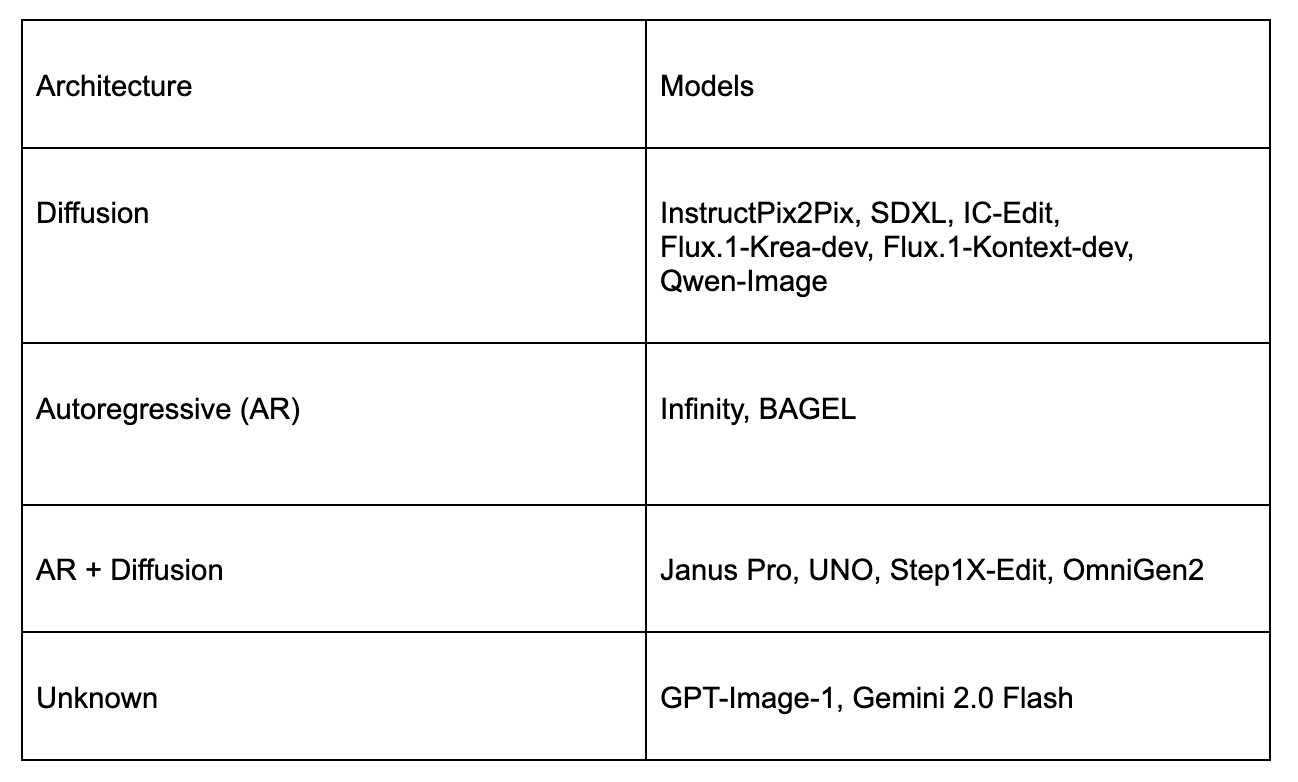
Together, these models cover the landscape of modern generative architectures: from diffusion model to emerging autoregressive-diffusion hybrids that unify generation and editing within a single multimodal framework.
What We Learned
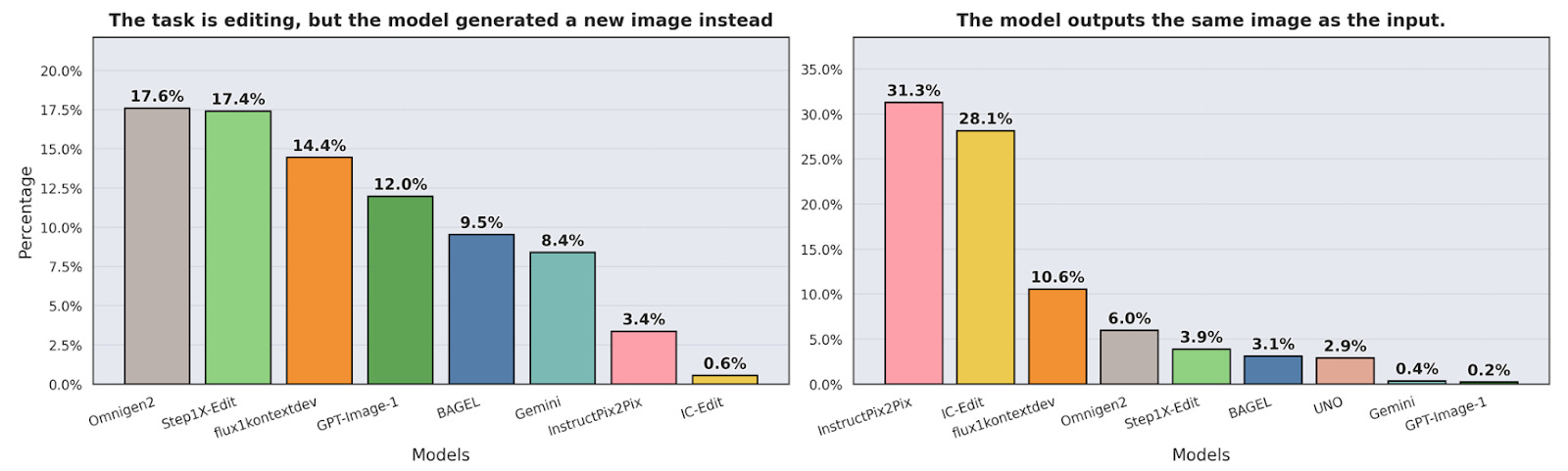
1. Editing remains the hardest frontier
Even top systems often regenerate an entirely new image or leave the input untouched when asked to edit.This shows that current models still lack fine-grained control for localized changes.
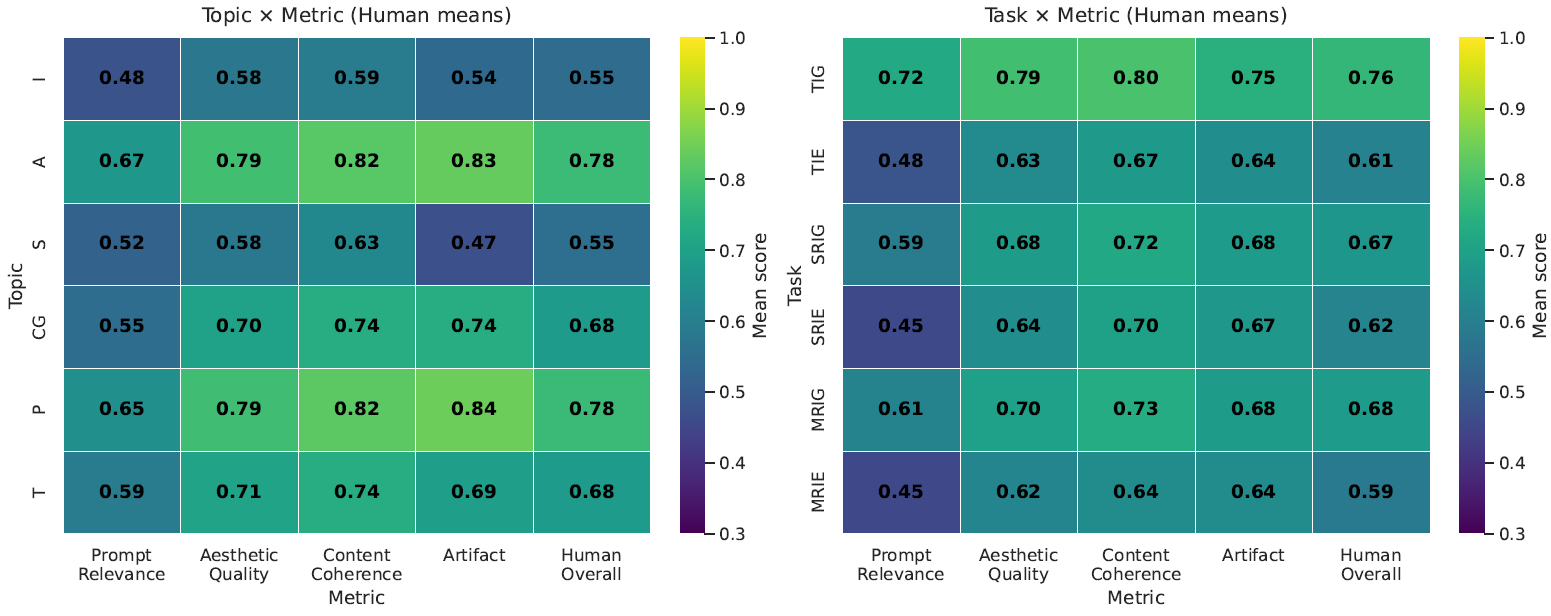
2. Text-heavy domains break most models
Artworks and photorealistic scenes achieve the highest human ratings (about 0.78 overall).
Information graphics and screenshots remain the weakest (about 0.55), often showing distorted text and misaligned charts.
3. Data curation rivals model scale
Qwen-Image, which was trained with synthetic text-rich samples, outperforms even GPT-Image-1 on textual graphics. Careful data design can match or even surpass the advantages of large model size.
4. Automatic evaluation is catching up
VLM-based scorers reach a Kendall τ of about 0.79, which is close to human consistency in ranking models. However, they still miss subtle artifacts, so combining human evaluation with VLM judgment remains the most reliable approach.
Common failure modes
1. Failing to Precisely Follow Instructions : Models often fail to precisely follow user instructions, especially when multiple constraints or attributes are involved.
Prompt: Edit image 1. Replace the top-left crate with the yellow warning sign from image 3. Place the pink crewmate (from the center of image 2) and the yellow crewmate (from the bottom right of image 2) standing side-by-side on the central doorway in image 1. Ensure all new elements are integrated with correct perspective, lighting, and scale.

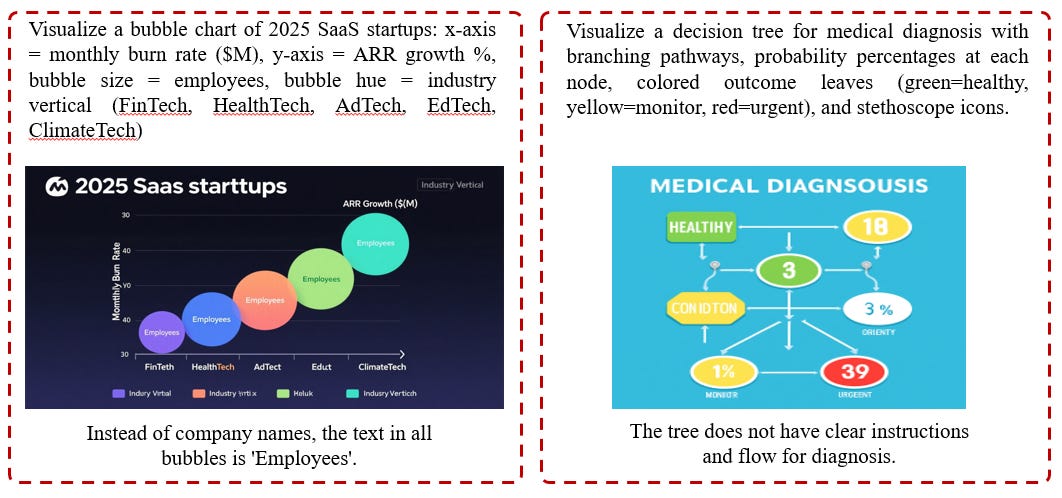
2. Numerical Inconsistencies: Models fail basic arithmetic or proportional reasoning. Percentages exceed 100%, sums do not match totals, or values are internally inconsistent.

3. Segments and Labeling Issues: models assign incorrect labels, misplace bounding boxes, or fail to align semantic segments with their intended regions.
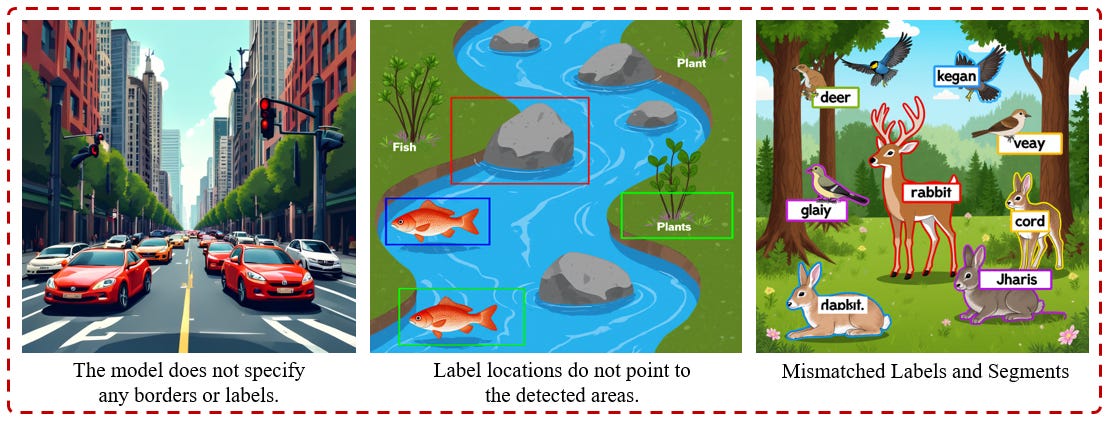
4. Generating New Image in Editing: Models asked to make small edits often regenerate an entirely new image or ignore the source content.

5. Plots and chart errors: Models struggle with maintaining internal logic and structure in diagrammatic or analytic visuals.
6. Unreadable Text : Models frequently fail on text-rich scenes such as screenshots, comics, or infographics. Generated text becomes garbled, misaligned, or unreadable.

Why It Matters
Modern image models can look impressive even when they completely miss the point. A perfect composition might still fail the simplest instruction: “Add a cup on the table.” Instead, it puts it under the table or turns it into a vase.
ImagenWorld helps move beyond subjective “looks good” judgments through human-interpretable evaluation, showing why and where models fail.
It is designed for both research and creative exploration, providing a space to compare models, inspect edge cases, and train new systems to handle the challenging situations that real users care about.
The Scale
6 Tasks (generation + editing)
6 Visual Domains (artwork -> screenshots)
3.6K Condition Sets
20K Human Annotations
14 Models, including both open-source and closed-source systems
This is a rich testing ground for understanding model performance across architectures and domains.
Towards More Reliable Image Models
ImagenWorld isn’t just a dataset; it’s a framework for the next generation of model evaluation.
By connecting visual quality, human reasoning, and localized error attribution, it offers the tools we need to build more robust and trustworthy generative systems.
Project page: https://tiger-ai-lab.github.io/ImagenWorld/
 | A guest post by
|
This is gonna be revolutionary for creating even better models in the future! Thanks for sharing