
New Open-Source Models Now in ComfyUI: VOID, BiRefNet & Gemma 4
Three powerful new open-source models are now ready to use in Comfy—modifying text, image, and video with ease

Big week for our open-source community! We’re excited to announce native ComfyUI support for three newly open-sourced models this week: Netflix’s VOID for video object removal, BiRefNet for high-resolution background segmentation, and Google’s Gemma 4 multimodal LLM. Here’s a look at what each one does and how to get started.
VOID: Video Object Removal with Accurate Physical Interactions
Netflix recently open-sourced VOID (Video Object and Interaction Deletion), a video inpainting model that goes further than simply erasing pixels. When you remove a subject, VOID also removes everything that subject physically caused in the scene: shadows, reflections, and objects that were set in motion by its presence.
The key to getting good inpainting is quadmask: instead of a standard binary mask, VOID takes a greyscale mask using four values that tell the model which regions to remove, which overlap, which are physically affected, and which to keep untouched. This lets the model reason about cause and effect rather than just filling in a hole. Pro tip: use video segmentation models such as SAM3 to generate initial mask input for quadmask.
VOID ships with two checkpoints. Pass 1 handles the base inpainting and is sufficient for most clips. Pass 2 adds optical flow-warped refinement for better temporal consistency on longer or more complex footage.
Getting Started
Update ComfyUI to the latest version, or visit Comfy Cloud
Download the model package from Comfy-Org/void-model and place the files in the correct model folders
Download the workflows below, or find them in the template.
Prepare your input video, quadmask, and a text prompt describing the scene after removal, then run the workflow
BiRefNet: High-Resolution Background and Object Segmentation
BiRefNet (Bilateral Reference Network) is a segmentation model from CAAI AIR 2024 that has become one of the most widely used image segmentation backbones in the open-source ecosystem.


BiRefNet is built for dichotomous image segmentation, extracting clean, high-resolution masks from complex images including fine detail like hair, fur, and transparent surfaces. The same model also handles salient object detection and camouflaged object detection, so it covers a wide range of masking tasks in a single lightweight package.
Getting Started
Download the model package from Comfy-Org/BiRefNet and place
birefnet.safetensorsin yourmodels/background_removal/folderDownload the workflows below, or find them in the template.
Drop in your image and run
Gemma 4: Google’s Multimodal Reasoning Model
Google DeepMind has released Gemma 4, the latest generation of their open-weights model family. Gemma 4 is natively multimodal -- handling text, image, audio, and video input -- and includes a configurable thinking mode that lets the model reason step by step before producing a response
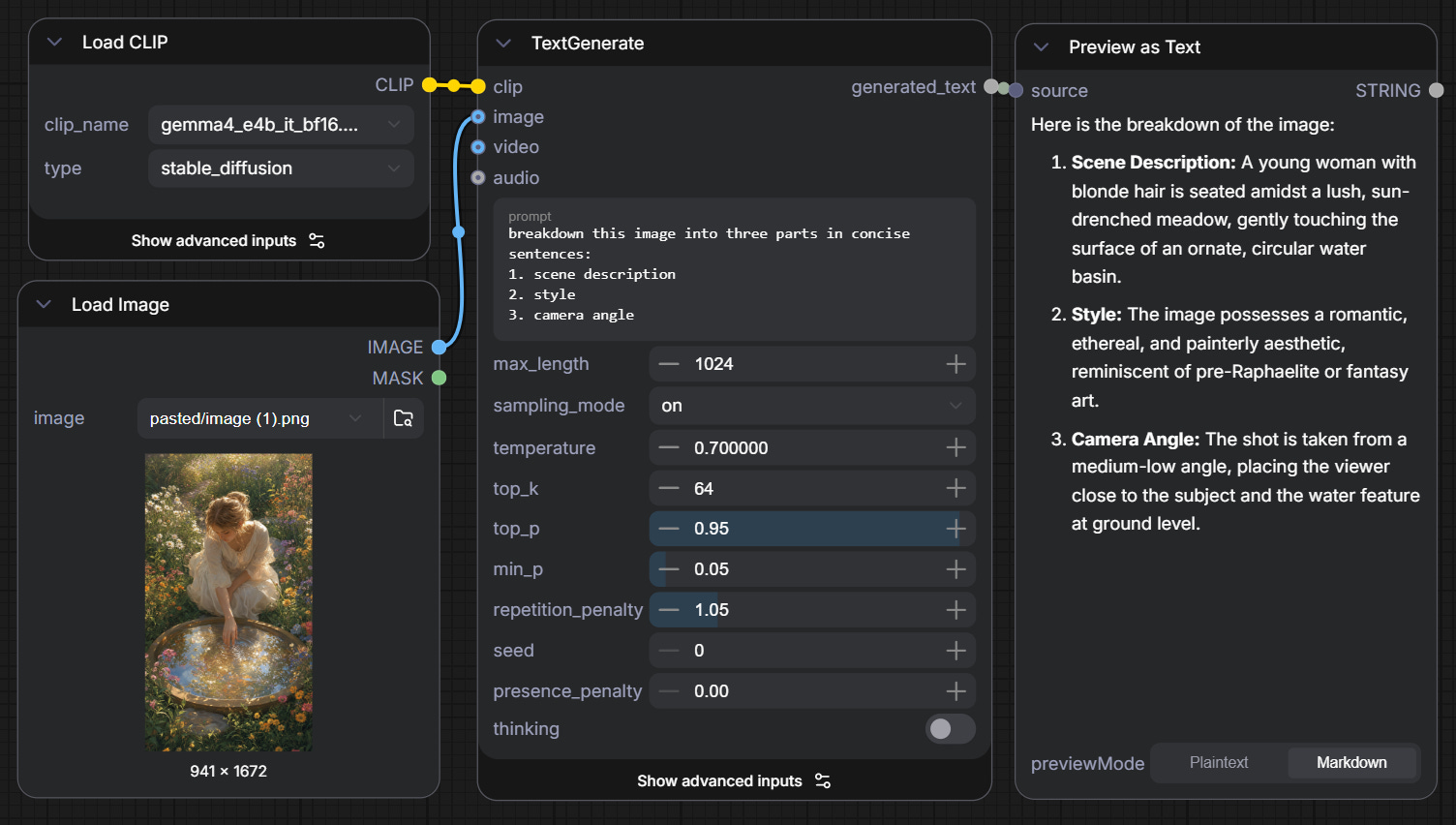
Gemma 4 models are out on ComfyUI as text encoders to be used with TextGenerate node. Two variants are available: E2B and E4B are parameter-efficient models and a good starting point for most consumer GPUs. Additionally, two more variants, the 26B A4B Mixture-of-Experts and 31B dense models, are available through Google’s official release.
Getting Started
Download the model package from Comfy-Org/gemma-4 and place the files in your
models/text_encoders/folderDownload the workflows below, or find them in the template.
Type in text instructions, wire in any optional images or videos, and run
As always, enjoy creating!
"When you remove a subject, VOID also removes everything that subject physically caused in the scene: shadows, reflections, and objects that were set in motion by its presence."
But the shadow of the man's arm and torso are still there on the bike's shadow...